توسعه مدلهای ترانسفورمر با پیشرفت چشمگیر عملکرد و قابلیتهای پردازش زبان طبیعی (NLP) تحول ایجاد کرده است. با این حال، این توسعه سریع چالشهای قابل توجهی را به ویژه در مورد نیازهای حافظه برای آموزش این مدلهای بزرگمقیاس ایجاد کرده است. با افزایش اندازه و پیچیدگی مدلهای ترانسفورمر، مدیریت نیازهای حافظه به طور فزایندهای حیاتی میشود. این مقاله با ارائه یک روش نوآورانه برای بهینهسازی استفاده از حافظه بدون به خطر انداختن عملکرد آموزش توالیهای طولانی، به این مسئله مهم میپردازد.
رویکردهای سنتی مانند توجه چندگانه و توجه گروهی پرس و جو (GQA) با بهینهسازی اندازه کش کلید-مقدار، استفاده از حافظه را در طول استنتاج به میزان قابل توجهی کاهش دادهاند. این تکنیکها با موفقیت در مدلهای بزرگمقیاس مانند PaLM و LLaMA پیادهسازی شدهاند. با این حال، بهبودهای مداوم در معماری مدل، مانند افزایش اندازه واژگان و لایههای میانی در Llama3، همچنان چالشهای حافظه را در طول آموزش تشدید میکند.
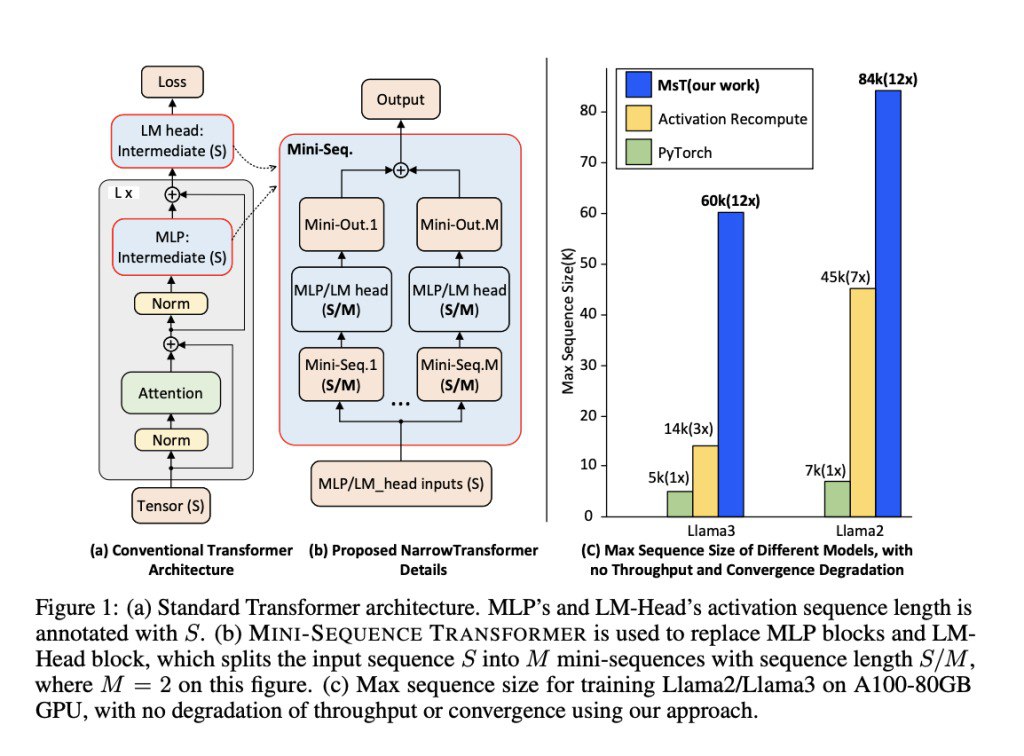
تیمی از محققان دانشگاه کالیفرنیا، برکلی و دانشگاه کارنگی ملون، مدل ترانسفورمر دنباله کوتاه (MST) را برای رسیدگی به این چالشها پیشنهاد میکنند. MST روشی را معرفی میکند که توالیهای ورودی را تقسیم کرده و آنها را به صورت تکراری به عنوان دنبالههای کوتاه پردازش میکند. این رویکرد با ادغام محاسبه مجدد فعالسازی، تکنیکی که شامل محاسبه مجدد فعالسازی برخی لایهها در گذر عقب است، استفاده از حافظه میانی را به طور قابل توجهی کاهش میدهد که در گذر جلو و عقب باعث صرفهجویی در حافظه میشود. MST طوری طراحی شده است که مستقل از پیادهسازی باشد و برای ادغام با فریمورکهای آموزشی موجود به تغییرات کد کمی نیاز دارد. این روش حتی هنگام برخورد با توالیهای بسیار طولانی، کارایی و دقت بالایی را حفظ میکند.
روش MST با تقسیم توالیهای ورودی به دنبالههای کوتاهتر، استفاده از حافظه را کاهش میدهد. در طول آموزش مدلهایی مانند Llama3-8B، حافظه اختصاص داده شده به فعالسازیها در گذر جلو قابل توجه است و چالشهای مشابهی در گذر عقب ایجاد میشود. MST با پردازش تکههای کوچکتر به صورت تکراری، این مسئله را کاهش میدهد، در نتیجه ردپای حافظه را کم میکند. این رویکرد همچنین شامل بهینهسازی حافظه اختصاص داده شده به گرادیانها و حالتهای بهینهساز است که کارایی کلی فرآیند آموزش را بیشتر بهبود میبخشد.
علاوه بر MST پایه، محققان این روش را به یک محیط توزیعشده گسترش میدهند. با ترکیب MST با DeepSpeed-Ulysses، تانسور ورودی هر لایه ترانسفورمر در امتداد بعد توالی تقسیم میشود که امکان محاسبه موازی در چندین GPU را فراهم میکند. این تقسیمبندی همراه با محاسبه مجدد فعالسازی منجر به کاهش قابل توجه نیازمندیهای حافظه فعالسازی میشود. MST سازگاری با تکنیکهای موازیسازی توالی مختلف مانند Megatron-LM و Ring Attention را حفظ میکند که اطمینان از مقیاسپذیری و انعطافپذیری در محیطهای آموزشی مختلف را تضمین میکند.
محققان آزمایشهای گستردهای برای تأیید اثربخشی MST انجام دادند. آنها مدلهای Llama3-8B و Llama2 را با MST آموزش دادند و قابلیتهای طول توالی را به طور قابل توجهی بهبود بخشیدند. برای مثال، MST امکان آموزش Llama3-8B با طول زمینه تا 60k روی یک GPU A100 را فراهم کرد که از نظر طول توالی نسبت به پیادهسازیهای استاندارد ۱۲ تا ۲۰ برابر بهتر عمل میکند. علاوه بر این، MST همان توان عملیاتی آموزش روشهای استاندارد آموزش توالی طولانی را حفظ کرد و اطمینان حاصل کرد که بهینهسازی به قیمت عملکرد انجام نشده است.
ارزیابی همچنین مقیاسپذیری MST در محیطهای توزیعشده را برجسته کرد. با استفاده از DeepSpeed-Ulysses، MST میتواند طول توالی را به طور خطی با تعداد GPUها مقیاس کند که پتانسیل آن را برای استقرار در مقیاس بزرگ نشان میدهد. بهینهسازی حافظه حاصل از MST به ویژه برای مؤلفه LM-Head قابل توجه بود که استفاده از حافظه را به طور قابل توجهی کاهش داد در حالی که تأثیر کمی بر زمان اجرای توالیهای طولانیتر داشت.







