در چشمانداز همیشه در حال تحول هوش مصنوعی (AI)، چالش ایجاد سیستمهایی که بتوانند به طور موثر در محیطهای پویا همکاری کنند، بسیار مهم است. یادگیری تقویتی چندعاملی (MARL) با هدف آموزش عاملها برای تعامل و سازگاری در چنین محیطهایی، یک تمرکز اصلی بوده است. با این حال، این روشها اغلب با پیچیدگی و مسائل سازگاری، به ویژه هنگام مواجهه با موقعیتهای جدید یا عاملهای دیگر، دست و پنجه نرم میکنند. در پاسخ به این چالشها، این مقاله از استنفورد رویکرد جدیدی به نام مدل «ذهنهای فرضی» را معرفی میکند. این مدل نوآورانه با استفاده از مدلهای زبانی بزرگ (LLM) برای بهبود عملکرد در محیطهای چندعاملی با شبیهسازی نحوه درک و پیشبینی رفتار دیگران توسط انسانها، عملکرد را ارتقا میدهد.
روشهای سنتی MARL اغلب در برخورد با محیطهای در حال تغییر مشکل دارند، زیرا اقدامات یک عامل میتوانند به طور غیرقابل پیشبینی بر دیگران تأثیر بگذارند. این بیثباتی یادگیری و سازگاری را چالشبرانگیز میکند. راهحلهای موجود، مانند استفاده از LLM برای هدایت عاملها، برخی از امیدها را در درک اهداف و برنامهریزی نشان دادهاند، اما هنوز به توانایی ظریف برای تعامل موثر با چندین عامل نیاز دارند.
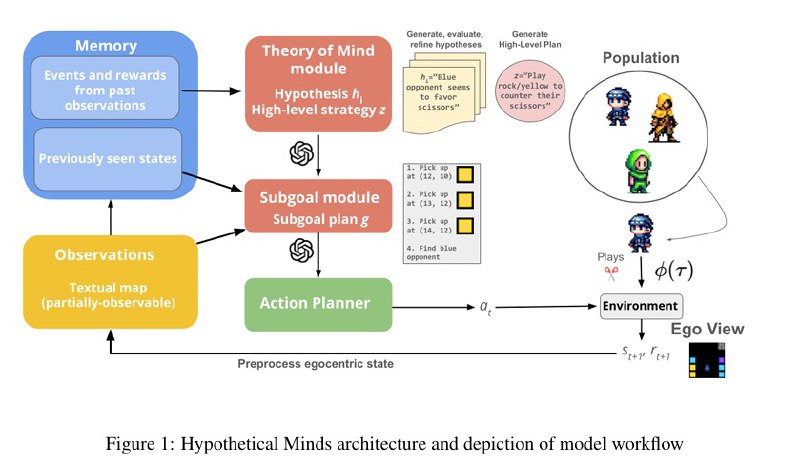
مدل ذهنهای فرضی یک راه حل امیدوارکننده برای این مسائل ارائه میدهد. این مدل یک ماژول تئوری ذهن (ToM) را در یک چارچوب مبتنی بر LLM ادغام میکند. این ماژول ToM به عامل اجازه میدهد تا با استفاده از زبان طبیعی، فرضیههایی درباره استراتژیها، اهداف و رفتارهای عاملهای دیگر ایجاد و بهروزرسانی کند. با اصلاح مداوم این فرضیهها بر اساس مشاهدات جدید، مدل استراتژیهای خود را در زمان واقعی تطبیق میدهد. این سازگاری در زمان واقعی یک ویژگی کلیدی است که منجر به بهبود عملکرد در سناریوهای همکاری، رقابت و انگیزههای مختلط میشود و اطمینان از عملی بودن و اثربخشی مدل را فراهم میکند.
مدل ذهنهای فرضی بر اساس چندین مؤلفه کلیدی از جمله ادراک، حافظه و ماژولهای برنامهریزی سلسله مراتبی ساخته شده است. مرکز عملکرد آن ماژول ToM است که مجموعهای از فرضیههای زبان طبیعی در مورد عاملهای دیگر را حفظ میکند. LLM این فرضیهها را بر اساس حافظه عامل از مشاهدات گذشته و فرضیههای قبلی با ارزش بالا تولید میکند. این فرآیند به مدل اجازه میدهد تا درک خود را از استراتژیهای عاملهای دیگر به صورت تکراری اصلاح کند.
این فرآیند به شرح زیر عمل میکند: عامل اقدامات عاملهای دیگر را مشاهده میکند و فرضیههای اولیهای درباره استراتژیهای آنها ایجاد میکند. این فرضیهها بر اساس میزان پیشبینی رفتارهای آینده توسط آنها ارزیابی میشوند. یک سیستم امتیازدهی دقیقترین فرضیهها را شناسایی میکند که در طول زمان تقویت و اصلاح میشوند. این تضمین میکند که مدل به طور مداوم سازگار میشود و درک خود را از عاملهای دیگر بهبود میبخشد.
سپس برنامههای سطح بالا بر اساس این فرضیههای اصلاحشده شرطی میشوند. رویکرد برنامهریزی سلسله مراتبی مدل این برنامهها را به زیر اهداف کوچکتر و عملی تبدیل میکند و استراتژی کلی عامل را هدایت میکند. این ساختار به مدل ذهنهای فرضی اجازه میدهد تا محیطهای پیچیده را موثرتر از روشهای سنتی MARL پیمایش کند.
برای ارزیابی اثربخشی ذهنهای فرضی، محققان از معیار MARL Melting Pot استفاده کردند که مجموعهای جامع از آزمایشها برای ارزیابی عملکرد عامل در سناریوهای تعاملی مختلف طراحی شده است. این موارد از کارهای هماهنگی ساده تا بازیهای استراتژیک پیچیده که نیازمند همکاری، رقابت و سازگاری هستند، متغیر بود. ذهنهای فرضی در سازگاری، تعمیم و عمق استراتژیک نسبت به روشهای سنتی MARL و سایر عاملهای مبتنی بر LLM عملکرد بهتری داشتند. در سناریوهای رقابتی، مدل به طور پویا فرضیههای خود را در مورد استراتژیهای حریفان بهروزرسانی کرد و حرکات آنها را چندین مرحله جلوتر پیشبینی کرد و به آن اجازه داد تا با پیشبینی استراتژیک برتر رقبای خود را شکست دهد.
این مدل همچنین در تعمیم به عاملها و محیطهای جدید، یک چالش برای رویکردهای سنتی MARL، برتری داشت. هنگام مواجهه با عاملهای ناشناخته، ذهنهای فرضی به سرعت فرضیههای دقیق تشکیل دادند و رفتار خود را بدون آموزش گسترده تنظیم کردند. ماژول تئوری ذهن قوی به برنامهریزی سلسله مراتبی اجازه داد تا مدل بتواند نیازها و اقدامات شرکا را به طور موثر پیشبینی کند.
