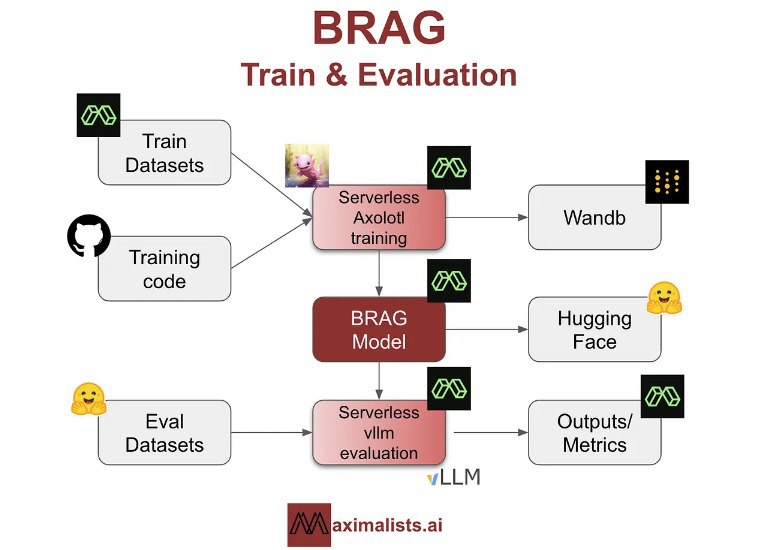
BRAG یک سری از مدلهای تولید تقویتشده با بازیابی (RAG) با کارایی بالا است که توسط محققان Maximalists AI توسعه یافته است. مدلهای BRAG خانوادهای از مدلهای زبانی کوچک (SLM) هستند که برای ارائه جایگزینهای مقرون به صرفه و با کارایی بالا در پردازش زبان مبتنی بر هوش مصنوعی طراحی شدهاند. این مدلها با هزینه چشمگیر کمتر از ۲۵ دلار برای هر کدام آموزش دیدهاند و آنها را به راهحلهای کارآمد و اقتصادی در هوش مصنوعی تبدیل کردهاند.
مدلهای BRAG در پاسخ به نیاز به مدلهای زبانی کارآمد و با کارایی بالا ایجاد شدهاند که به منابع محاسباتی گسترده معمولاً مرتبط با مدلهای بزرگمقیاس مانند مدلهای Nvidia و OpenAI نیاز ندارند. انگیزه اصلی پشت BRAG توسعه سری مدلهایی بود که بتوانند با عملکرد مدلهای پیشرو مانند Cohere’s Command R+, Qwen2، Llama3.1 و Llama3 Instruct مطابقت داشته یا از آنها پیشی بگیرند، در حالی که هزینههای آموزش را حداقل نگه دارند.
ادامه مقاله را در سایت رومند بخوانید….
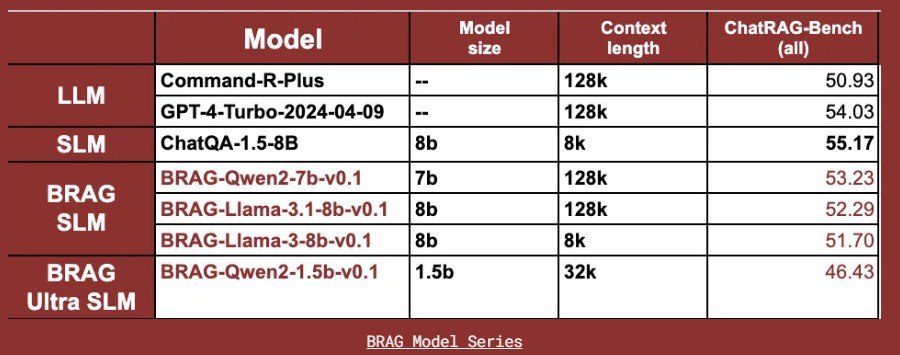
سری BRAG شامل چهار مدل است:
BRAG-Qwen2-7b-v0.1
BRAG-Llama-3.1-8b-v0.1
BRAG-Llama-3-8b-v0.1
BRAG-Qwen2-1.5b-v0.1
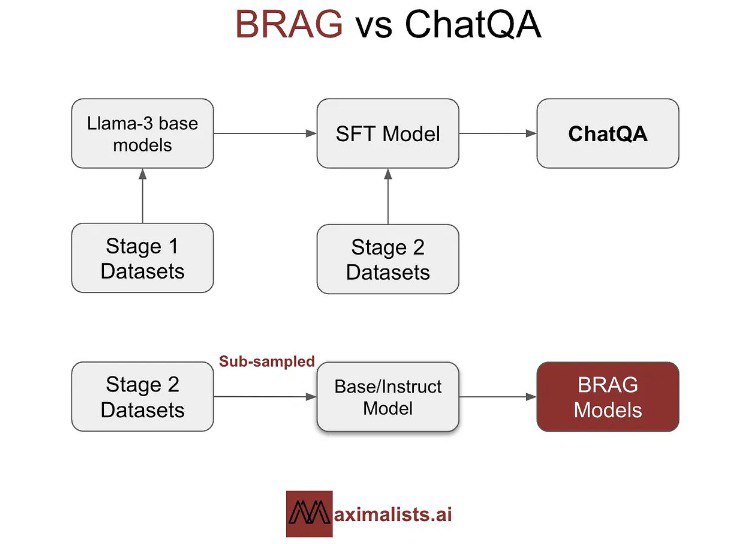
این مدلها بر اساس عملکرد آنها در معیارهای باز و توانایی آنها در ایجاد تعادل بین کارایی و قابلیت انتخاب شدهاند. مدلها تحت یک فرآیند تنظیم دقیق دو مرحلهای الهام گرفته از رویکرد ChatQA Nvidia قرار گرفتند که شامل آموزش اولیه روی مجموعه دادههای دستورالعمل عمومی و سپس مجموعه دادههای خاص RAG است.
مدلهای BRAG به ویژه برای عملکرد خود نسبت به اندازه آنها قابل توجه هستند. مدلهای ۱.5B تعادل عالی بین عملکرد و کارایی را ارائه میدهند. در مقایسه، مدلهای 7B و 8B میتوانند وظایف پیچیدهتری مانند درک متن طولانی، تفسیر دادههای جدولی و استدلال ریاضی را مدیریت کنند. این انتخاب استراتژیک مدلها و روششناسی آموزش به Maximalists اجازه داد تا عملکرد را بهینه کرده و در عین حال هزینهها را به طور موثر مدیریت کند.
آموزش مدل BRAG شامل تکنیکهای LoRA (Low-Rank Adaptation) و QLoRA (quantized LoRA) بود. LoRA با سادهسازی ماتریسهای تطبیقی، آموزش سریعتر با تقاضای محاسباتی کمتر را امکانپذیر میکند. در مقابل، QLoRA پارامترهای وزن را به دقت ۴ بیتی فشرده میکند که به طور قابل توجهی فضای حافظه را کاهش میدهد و آموزش روی GPUهای مصرفکننده را تسهیل میکند.
مدلها با استفاده از ChatRAG-Bench، یک معیار طراحیشده برای ارزیابی QA مکالمهای و قابلیتهای RAG در انواع مختلف اسناد و فرمتهای سوال، ارزیابی شدند. معیارهای ارزیابی شامل F1-Score و دقت تطابق دقیق بود که بینشهایی در مورد توانایی مدلها در تولید پاسخهای دقیق و مرتبط با زمینه ارائه کرد.
چالشها، بهبودها و آینده BRAG
در طول فرآیند آموزش، چندین چالش از جمله مدیریت اسناد طولانی، تفسیر دادههای جدولی و رسیدگی به پرسوجوهای خاص دامنه مواجه شد. این مسائل با انتخاب دقیق مجموعه داده و آزمایش با ترکیبات مختلف داده کاهش یافت. به عنوان مثال، گنجاندن مجموعه دادههایی مانند DROP، Quoref و SQuAD به بهبود توانایی مدلها در مدیریت انواع دادههای پیچیده و متنوع کمک کرد. معیار امتیاز F1، در حالی که به طور گسترده پذیرفته شده است، دارای محدودیتهایی در ثبت تفاوتهای ظریف معنایی و زمینه بود. این امر نیاز به معیارهای ارزیابی جامعتر و آگاه از زمینه برای سنجش بهتر عملکرد مدل را برجسته کرد.
در نتیجه، Maximalists قصد دارد مدلهای BRAG را با بهبود عملکرد RAG و مدیریت دادههای جدولی و معرفی تولید استناد برای تفسیر بهتر ارتقا دهد. آنها همچنین قصد دارند تکنیکهای بازنویسی پرس و جو را برای بهبود دقت و مرتبط بودن جستجو اصلاح کنند. توسعه BRAG با اعتبارات Modal Labs پشتیبانی شد که آزمایش مقرون به صرفه را تسهیل کرد. با استفاده از تکنیکهای آموزشی نوآورانه و انتخاب استراتژیک مدل، BRAG نشان داده است که میتوان به عملکرد برتر با حداقل هزینه منابع دست یافت و راه را برای راهحلهای هوش مصنوعی در دسترستر و کارآمدتر هموار کرد.