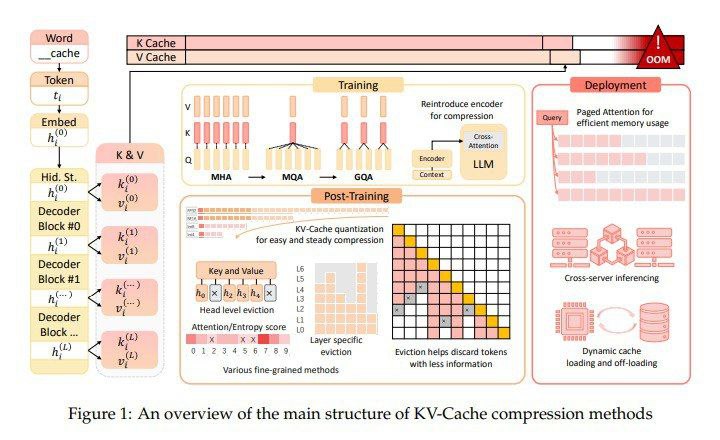
تیم تحقیقاتی از دانشگاه ووهان و دانشگاه جیائوتونگ شانگهای چندین روش فشردهسازی کش KV را معرفی کردهاند. این روشها استفاده از فضای کش KV را در مراحل پیشآموزش، استقرار و استنتاج LLMها بهینه میکنند تا با حفظ عملکرد، کارایی را افزایش دهند. رویکرد آنها شامل اصلاح معماری مدل در طول پیشآموزش برای کاهش اندازه بردارهای کلید و مقدار تا ۷۵ درصد است. این تنظیم مزایای مکانیسم توجه را حفظ میکند در حالی که نیازمندیهای حافظه را به طور قابل توجهی کاهش میدهد.
روشهای پیشنهادی شامل تنظیمات معماری در طول پیشآموزش است که اندازه بردارهای کلید و مقدار تولید شده را کاهش میدهد. در طول استقرار، فریمورکهایی مانند Paged Attention و DistKV-LLM کش KV را در چندین سرور توزیع میکنند تا مدیریت حافظه را بهبود بخشند. روشهای پس از آموزش شامل استراتژیهای تخلیه پویا و تکنیکهای کمّیسازی هستند که کش KV را بدون از دست دادن قابل توجه قابلیتهای مدل فشرده میکنند. به طور خاص، Paged Attention از یک جدول نگاشت برای ذخیرهسازی ناپیوسته کش KV در حافظه GPU استفاده میکند که باعث کاهش تکهتکه شدن و بهبود سرعت استنتاج میشود. DistKV-LLM با فعال کردن استقرار توزیع شده در سرورها و افزایش کارایی خدمات ابری در مقیاس بزرگ، این روش را گسترش میدهد.

روشهای معرفی شده بهبود قابل توجهی در کارایی حافظه و سرعت استنتاج نشان دادهاند. برای مثال، روش GQA که در مدلهای محبوب مانند LLaMA2-70B استفاده میشود، با کاهش اندازه کش KV در حالی که سطح عملکرد را حفظ میکند، از استفاده بهتر حافظه بهره میبرد. این بهینهسازیها پتانسیل رسیدگی موثرتر به زمینههای طولانیتر را نشان میدهند. به طور خاص، GQA استفاده از حافظه را به کسری از آنچه در روشهای سنتی نیاز است کاهش میدهد و به کاهش ۷۵ درصدی اندازه کش KV دست مییابد. علاوه بر این، مدلهایی که از Multi-Query Attention (MQA) و GQA استفاده میکنند، توان عملیاتی بهبود یافته و تأخیر کاهشیافته را نشان میدهند که معیارهای مهمی برای کاربردهای بلادرنگ هستند. تحقیقات نشان میدهد که استفاده از حافظه در هر توکن مدل LLaMA2-70B از ۰.۵ مگابایت به ۰.۱۲۵ مگابایت کاهش مییابد که نشاندهنده افزایش قابل توجهی در کارایی است.
این تحقیق استراتژیهای جامعی برای بهینهسازی کش KV در LLMها ارائه میدهد که به مسئله سربار حافظه رسیدگی میکند. با پیادهسازی این روشها، LLMها میتوانند به کارایی بالاتر و عملکرد بهتر دست یابند و راه را برای راهحلهای هوش مصنوعی پایدارتر و مقیاسپذیرتر هموار کنند. یافتههای دانشگاه ووهان و دانشگاه جیائوتونگ شانگهای نقشه راهی برای پیشرفتهای آینده ارائه میدهند و بر اهمیت مدیریت موثر حافظه در تکامل فناوری مدلهای زبانی بزرگ تأکید میکنند. این استراتژیها نه تنها محدودیتهای فعلی را کاهش میدهند بلکه مسیرهایی را برای کاوش در کاربردهای پیچیدهتر LLMها در صنایع مختلف باز میکنند.
